29 oktober 2024
Seminarium med NSVA och Hydrologisektionen

Fredrik Sahl
Flow Below

Den 23 oktober 2024 höll NSVA och WANDA ett seminarium anordnat av Hydrologisektionen, där Fredrik Sahl presenterade WANDA-projektet. Här följer en kort sammanfattning av vad han presenterade.
WANDA – Vad är det?
En applikation för att hantera fel i tidsseriedata, där hantering omfattar både identifiering och reparation av felen.
Vilka typer av fel är det tänkt att WANDA ska hantera?
Internt har vi definierat två olika typer av fel som WANDA ska kunna hantera:
Anomalier
Avvikelser
Anomalier
Anomalier är tydliga fel, till exempel när data visar omöjliga värden eller uppenbara tekniska fel.
Följande bilder visar exempel på hur en anomali identifieras och repareras genom att rekonstruera den förlorade datan.
Identifiera fel.
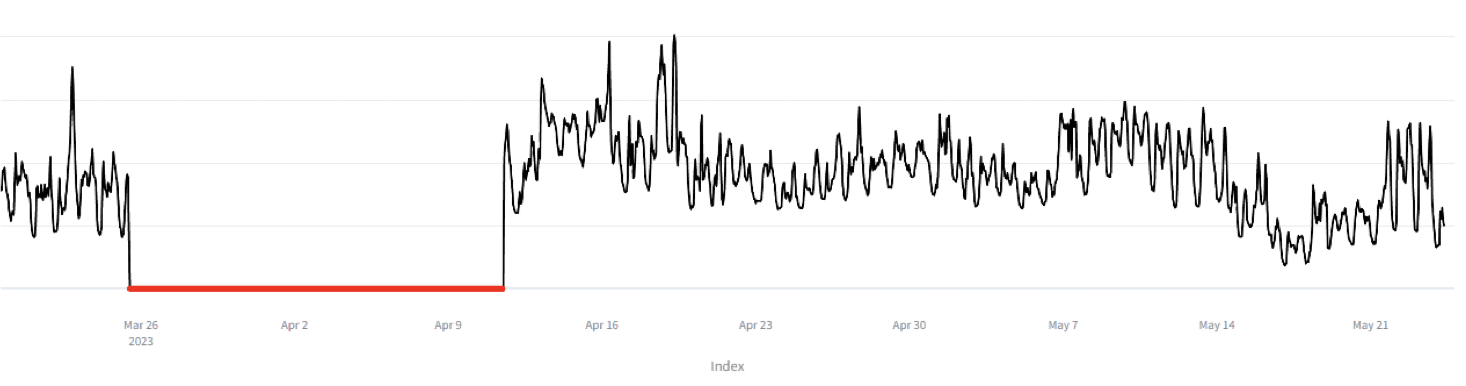
Reparera fel.
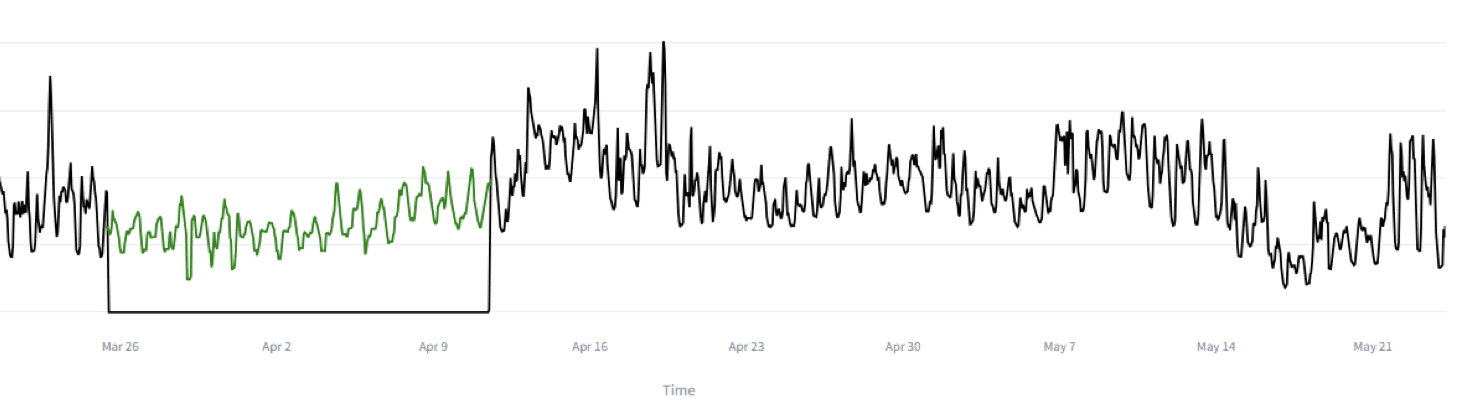
Avvikelser
Det är inte ovanligt att mätdata innehåller fel eller avvikelser som är svåra att upptäcka. Ofta kan dessa avvikelser dölja sig i naturliga variationer (väder m.m) vilket försvårar identifieringsprocessen. Varierande datakvalitet resulterar i sin tur i otillförlitlig data.
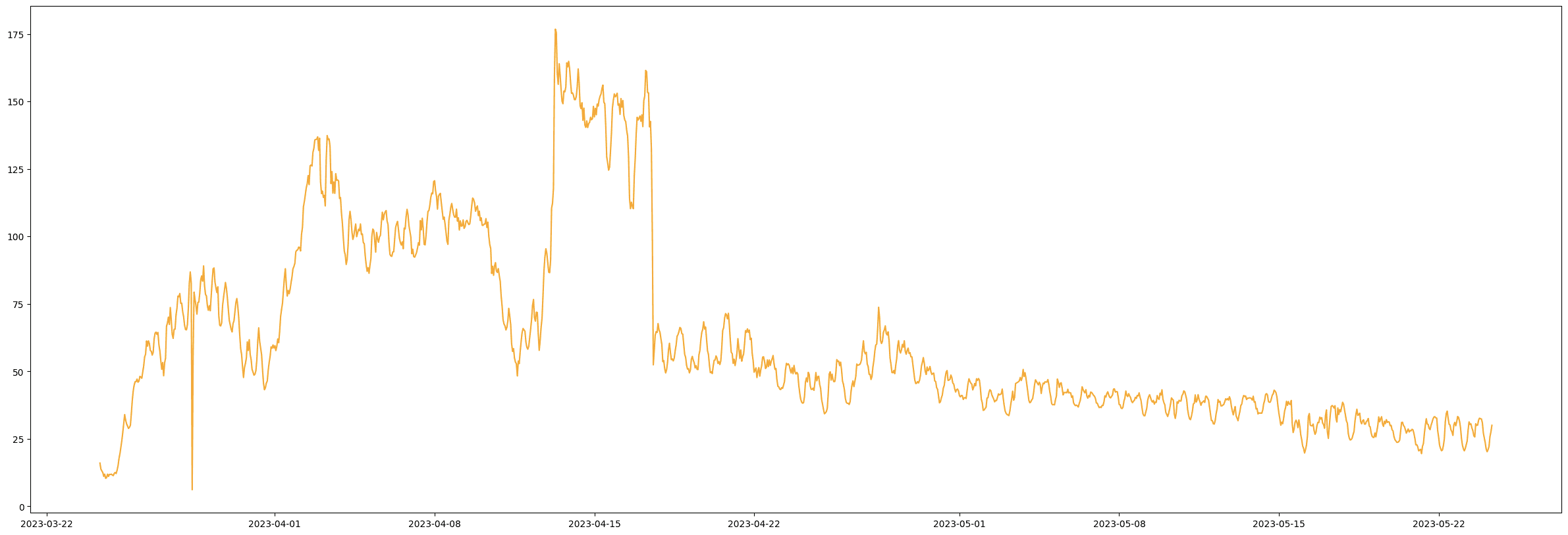
Som ni ser nedan kan avvikelser vara betydligt mer subtila. För att illustrera detta, överväg följande fråga:
Vilken av nedanstående mätserier innehåller felaktig data?
Figur 1.
Figur 2.
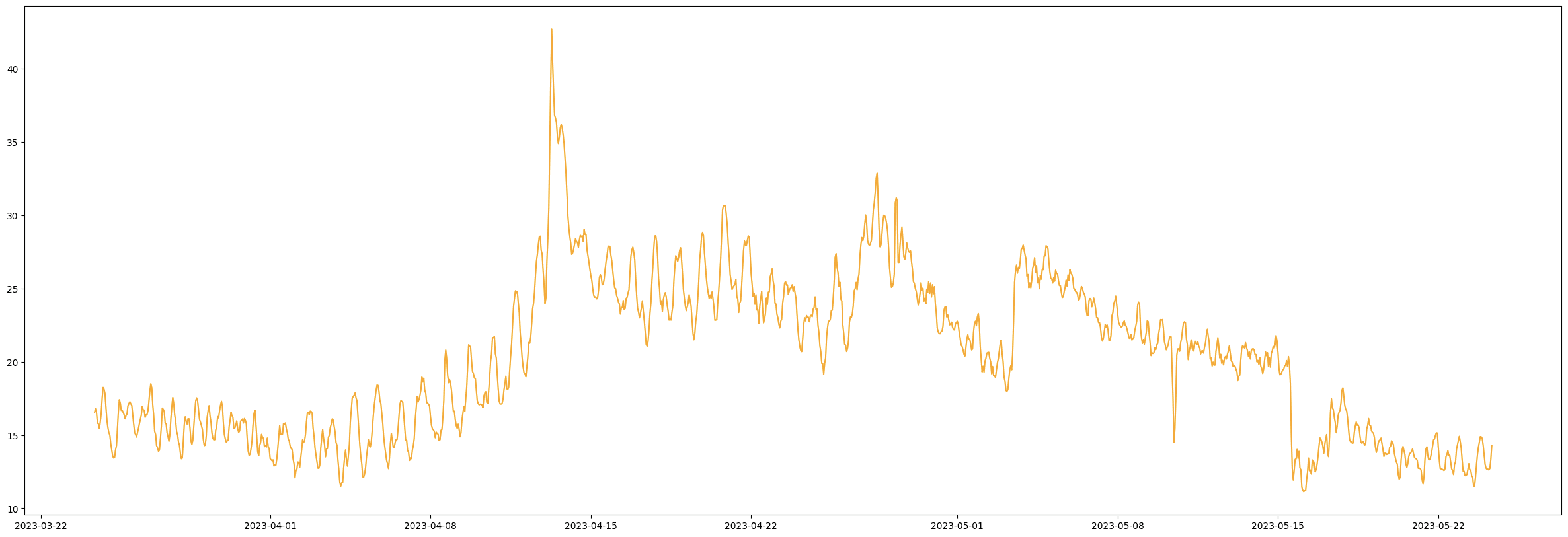
Svar: Figur 1 (se Figur 4 för ytterligare förklaring). Under projektets gång har vi insett att även erfarna VA-ingenjörer har svårt för att identifiera felaktig data utan att ha en tydlig kontext i form av t.ex. en tidsserie från en sensor nedströms.
Vi använder data vi kan lita på!
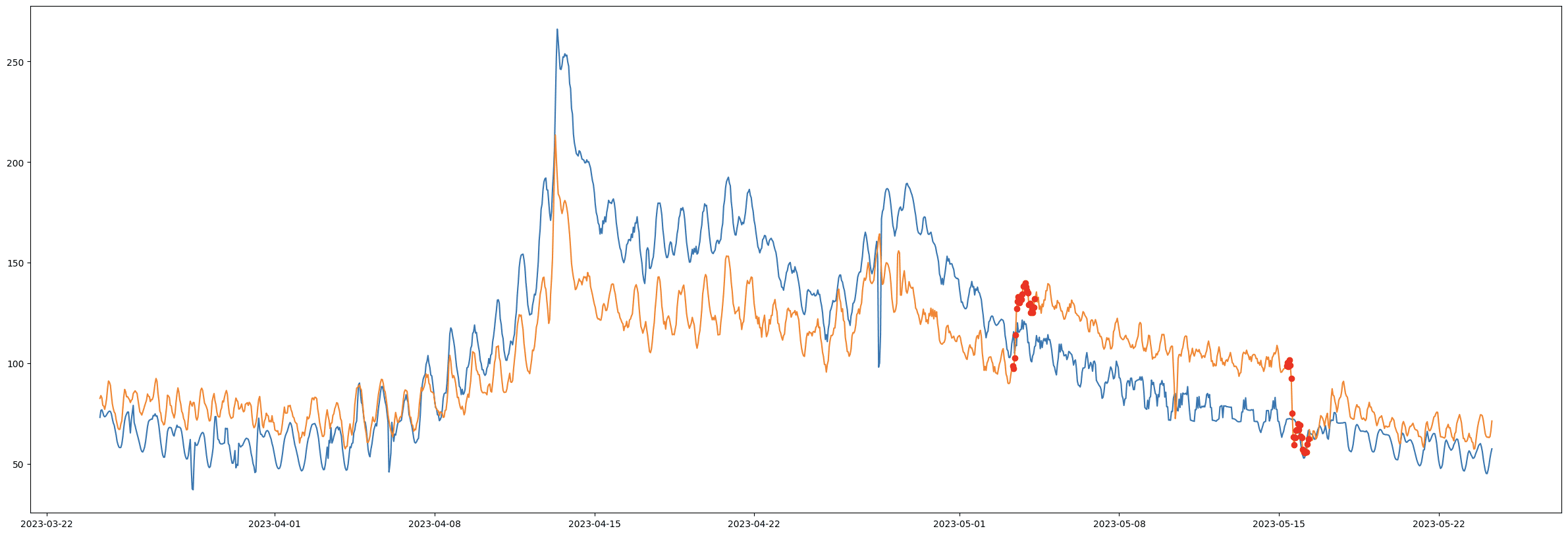
Det är ett rimligt antagande att det finns tidsserier där vi med stor sannolikhet kan säga att datakvaliteten är hög, exempelvis signaler från MAG-mätare. Vår analys grundar sig på tillförlitligheten i dessa dataset för att identifiera komplexa avvikelser (se Figur 3). Sen finns det även signaler som måste rapporteras till myndigheter, dessa tenderar också att ha en hög datakvalitet.
Figur 3.
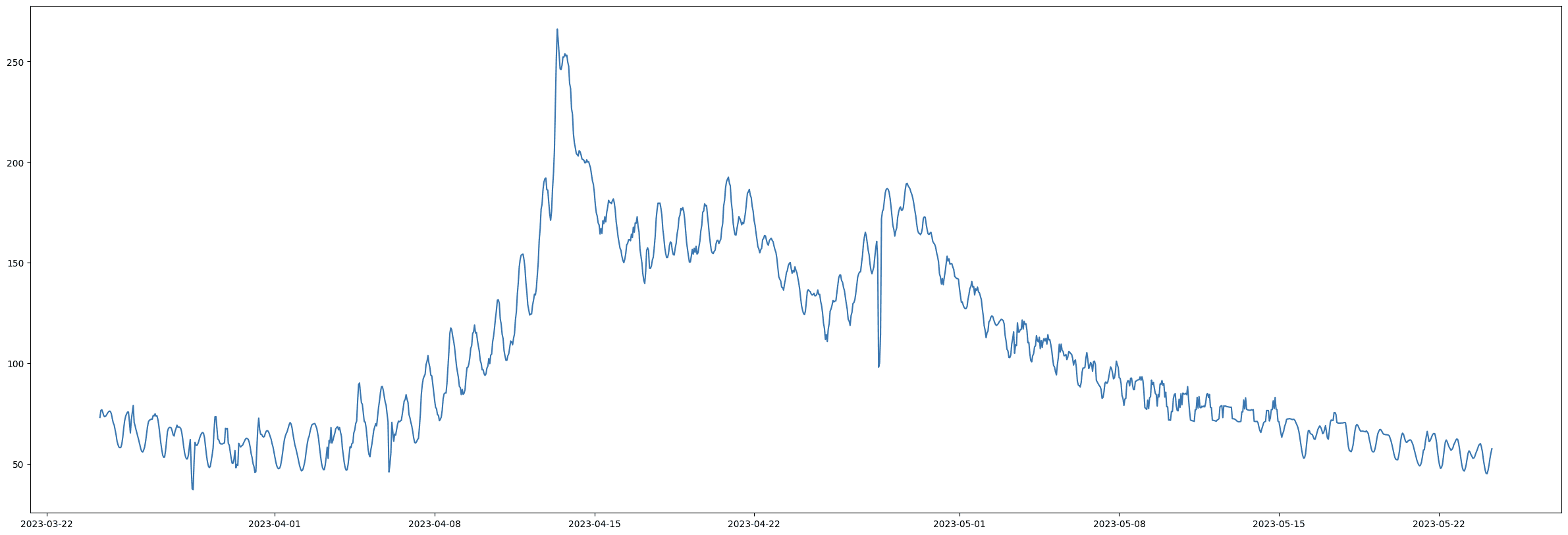
I Figur 4 och Figur 5 används en metod som kallas Dynamic Time Warping with Sliding Window för att jämföra en pålitlig tidsserie (se Figur 3) med en osäker tidsserie (se Figur 1). Analysen identifierar en avvikelse som beror på en blockerad barometrisk trycksensor. I Figur 5 noteras dessutom en temporär flödesökning i slutet av mätserien, orsakad av en förbipumpning.
Figur 4. - Dålig data, barometrisk trycksensor blockerad.
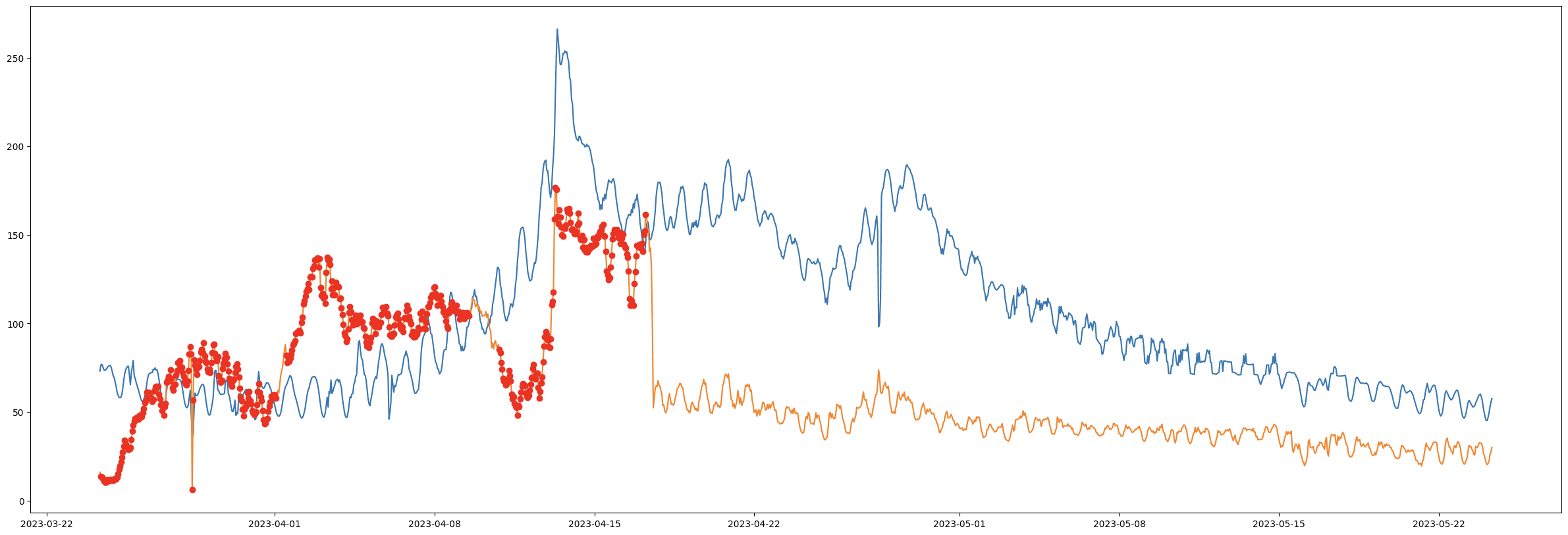
Figur 5. - Bra data, förbipumpning detekterad.
Lärdomar
Att förbättra datakvaliteten genom att identifiera och korrigera fel är en alltför omfattande uppgift eftersom begreppet "fel" är alltför brett definierat.
”Ett fel kan vara mätfel”
”Ett fel kan vara driftstörning, pumphaveri, vattenläcka…”
”Ett fel kan vara saknade värden”
All annoterad data är mycket värdefull. Även om datamängden är stor och erbjuder gott om material att träna på, är det viktigt att ha ett facit för att kunna utvärdera modellernas effektivitet korrekt.
”Det har varit svårt att producera stora mängder annoterad data.”
”Vi har massor av data…
men den är inte så värdefull om den inte är annoterad”
Vad kan vi göra med WANDA?
Städa data från felaktigheter och orimliga värden.
Identifiera avvikande mönster som kan indikera problem.
Reparera data så att den blir användbar igen.
Värdet av WANDA
Genom att använda WANDA kan vi öka värdet på data genom att göra den mer tillförlitlig och användbar. Detta sparar också tid för VA- och ML-ingenjörer, som annars skulle behöva lägga ner tid på manuell dataanalys och felsökning.
Vad är nästa steg?
Nästa steg är att paketera algoritmerna till ett bibliotek, implementera dem i en operationell miljö, och skapa en avvikelsekatalog för att underlätta identifiering och hantering av framtida problem.